Managing Data in R
Raw data is typically not available as R data files. If your data has been extracted from a database, you will most likely receive it as flat text files, e.g., csv files. Data recording web activity is often stored in a format called json. In this section we will look at how to easily read data files into R’s memory and how to store them as R databases.
You can download the code and data for this module as an Rstudio project here (download this zipped file and extract it - you can then open up the Rstudio project from Rstudio.)
Reading Raw Data into R
One of the most popular files formats for exchanging and storing data are comma-separated values files or CSV files. This is a left-over from the days of spreadsheets and is not a particularly efficient storage format for data but it is still widely used in businesses and other organizations. In a CSV file the first row contains the variable names. The next row contains the observations for the first record, separated by commas and then the next row for the second record and so on.
CSV files are straightforward to read into R. The fastest method for doing so is using the read_csv function contained in the tidyverse library set so let’s load this library:
#install.packages("tidyverse") ## only if you have not already installed this package
library(tidyverse)Case Study: Airbnb Data
 Let’s look at some data from the peer-to-peer house rental service Airbnb. There are different ways to obtain data on Airbnb listings. The most direct way is, of course, by working for Airbnb so you can access their servers directly. Alternatively, you can scrape data of the Airbnb website (as long as it doesn’t violate the terms of service of the site) or obtain the data through third parties. Here we will follow the last approach. The website Inside Airbnb provides Airbnb data from most of the major markets where Airbnb operate. Let’s focus on the San Diego listings. The data for each market is provided on the Get the Data page of the website. Go there and scroll down to San Diego. There are several files available - let’s focus on the “detailed listings” data in the file listings.csv.gz. This is a compressed CSV file. Download this file and unzip the compressed file - this will generate a file called listings.csv (note: this has already been done in the associated project and the files can be found in the data folder).
Let’s look at some data from the peer-to-peer house rental service Airbnb. There are different ways to obtain data on Airbnb listings. The most direct way is, of course, by working for Airbnb so you can access their servers directly. Alternatively, you can scrape data of the Airbnb website (as long as it doesn’t violate the terms of service of the site) or obtain the data through third parties. Here we will follow the last approach. The website Inside Airbnb provides Airbnb data from most of the major markets where Airbnb operate. Let’s focus on the San Diego listings. The data for each market is provided on the Get the Data page of the website. Go there and scroll down to San Diego. There are several files available - let’s focus on the “detailed listings” data in the file listings.csv.gz. This is a compressed CSV file. Download this file and unzip the compressed file - this will generate a file called listings.csv (note: this has already been done in the associated project and the files can be found in the data folder).
Now that you have downloaded the required file you can read the data into R’s memory by using the read_csv command:
SDlistings <- read_csv(file = 'data/listings.csv')This will create a data frame in R’s memory called SDlistings that will contain the data in the CSV file. This code assumes that the downloaded (and uncompressed) CSV file is located in the “data” sub-folder of the current working directory. If the file is located somewhere else that is not a sub-folder of your working directory, you need to provide the full path to the file so R can locate it, for example:
SDlistings <- read_csv(file = 'C:/Mydata/airbnb/san_diego/listings.csv')Our workflow above was to first first download the compressed file, then extract it and then read in the uncompressed file. You actually down need to uncompress the file first - just can also just read in the compressed file directly:
SDlistings <- read_csv(file = 'M:/data/airbnb/listings.csv.gz')This is a huge advantage since you can then store the raw data in compressed format.
If you are online you don’t even need to download the file first - R can read it off the source website directly:
file.link <- "http://data.insideairbnb.com/united-states/ca/san-diego/2016-07-07/data/listings.csv.gz"
SDlistings <- read_csv(file = file.link)Once you have read in raw data to R, it is highly recommended to store the original data in R’s own compressed format called rds. R can read in these files extremely fast. This way you only need to read in the original data file once. So the recommended workflow would be
## only run this section once! ------------------------------------------------------------------------
file.link <- "http://data.insideairbnb.com/united-states/ca/san-diego/2016-07-07/data/listings.csv.gz"
SDlistings <- read_csv(file = file.link) # read in raw data
saveRDS(SDlistings,file='data/listingsSanDiego.rds') # save as rds file
## start here after you have executed the code above once ---------------------------------------------
AirBnbListingsSD <- read_rds('data/listingsSanDiego.rds') # read in rds file What fields are available in this data? You can see this as
names(AirBnbListingsSD)## [1] "id" "listing_url"
## [3] "scrape_id" "last_scraped"
## [5] "name" "summary"
## [7] "space" "description"
## [9] "experiences_offered" "neighborhood_overview"
## [11] "notes" "transit"
## [13] "access" "interaction"
## [15] "house_rules" "thumbnail_url"
## [17] "medium_url" "picture_url"
## [19] "xl_picture_url" "host_id"
## [21] "host_url" "host_name"
## [23] "host_since" "host_location"
## [25] "host_about" "host_response_time"
## [27] "host_response_rate" "host_acceptance_rate"
## [29] "host_is_superhost" "host_thumbnail_url"
## [31] "host_picture_url" "host_neighbourhood"
## [33] "host_listings_count" "host_total_listings_count"
## [35] "host_verifications" "host_has_profile_pic"
## [37] "host_identity_verified" "street"
## [39] "neighbourhood" "neighbourhood_cleansed"
## [41] "neighbourhood_group_cleansed" "city"
## [43] "state" "zipcode"
## [45] "market" "smart_location"
## [47] "country_code" "country"
## [49] "latitude" "longitude"
## [51] "is_location_exact" "property_type"
## [53] "room_type" "accommodates"
## [55] "bathrooms" "bedrooms"
## [57] "beds" "bed_type"
## [59] "amenities" "square_feet"
## [61] "price" "weekly_price"
## [63] "monthly_price" "security_deposit"
## [65] "cleaning_fee" "guests_included"
## [67] "extra_people" "minimum_nights"
## [69] "maximum_nights" "calendar_updated"
## [71] "has_availability" "availability_30"
## [73] "availability_60" "availability_90"
## [75] "availability_365" "calendar_last_scraped"
## [77] "number_of_reviews" "first_review"
## [79] "last_review" "review_scores_rating"
## [81] "review_scores_accuracy" "review_scores_cleanliness"
## [83] "review_scores_checkin" "review_scores_communication"
## [85] "review_scores_location" "review_scores_value"
## [87] "requires_license" "license"
## [89] "jurisdiction_names" "instant_bookable"
## [91] "cancellation_policy" "require_guest_profile_picture"
## [93] "require_guest_phone_verification" "calculated_host_listings_count"
## [95] "reviews_per_month"Each record is an AirBnb listing in San Diego and the fields tell us what we know about each listing.
Reading Excel Files
Excel files can be read using the read_excel command. You can read separate sheets from the Excel file by providing an optional sheet number. The Excel file used below contains data from a 2015 travel decision survey conducted in San Francisco (the file was downloaded from Data.Gov from this link). Let’s read in this data and plot the distribution of total number of monthly trips taken by the survey respondents:
library(readxl) # library for reading excel files
file.name <- "data/TDS_202015_20Data-WEBPAGE.xlsx"
survey.info <- read_excel(file.name,sheet = 1)
survey.data <- read_excel(file.name,sheet = 2)
survey.dict <- read_excel(file.name,sheet = 3)
ggplot(data=survey.data,aes(x=Trips)) +
geom_histogram() +
labs(title='Distribution of Monthly Number of Trips',
subtitle=paste0('N=',nrow(survey.data),' Respondents')
)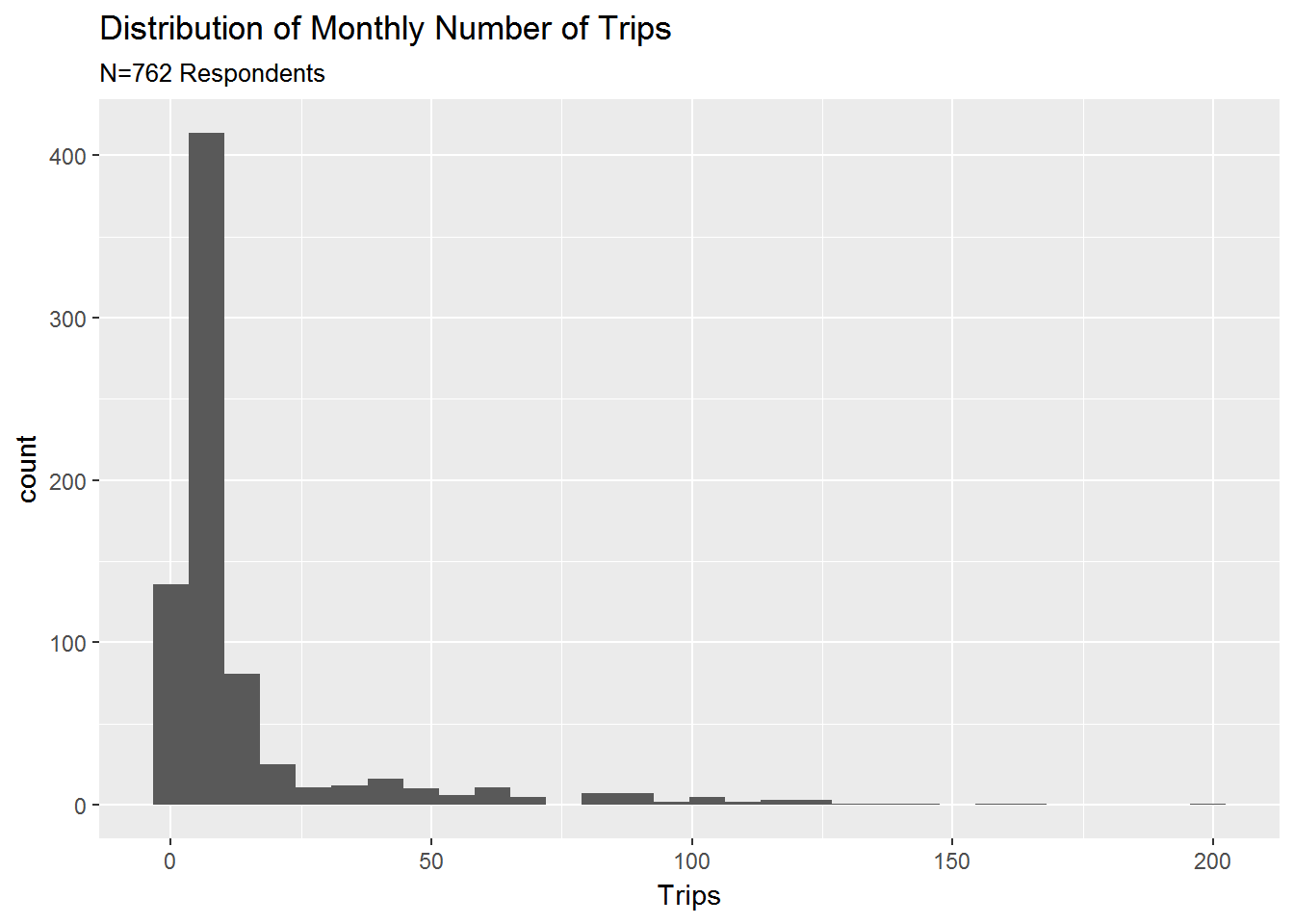
The first sheet contains some basic information about the survey, the second contains the actual survey response data, while the third sheet contains the data dictionary. The trip distribution is quite skewed with most respondents taking very few trips (note: the ggplot command is the main plot command in the ggplot library - an extremely powerful visualization package. You will learn all the details about visualization using ggplot in a later module).
Reading JSON files
JSON is short for Java-Script-Object-Notation and was originally developed as a format for formatting and storing data generated online. It is especially useful when handling irregular data where the number of fields varies by record. There are different methods to read these files - here we will use the jsonlite package.
Case Study: Food and Drug Administration Data
The Food and Drug Administration (FDA) is a government agency with a number of different responsibilities. Here we will focus on the “F” part, i.e., food. The FDA monitors and records data on food safety including production, retail and consumption. Since the FDA is a government agency - in this case dealing with issues that are not related to national security - it means that YOU as a citizen can access the data the agency collects.
You can find a number of different FDA datasets to download on https://open.fda.gov/downloads/. These are provided as JSON files. Here we focus on the Food files. There are two: One for food events and one for food enforcement. The food event file contains records of individuals who have gotten sick after consuming good. The food enforcement file contains records of specific types of food that has been recalled. Let’s get these data into R:
library(jsonlite)
enforceFDA <- fromJSON("data/food-enforcement-0001-of-0001.JSON", flatten=TRUE)
## or
enforceFDA <- fromJSON(unzip("data/food-enforcement-0001-of-0001.json.zip"), flatten=TRUE)
eventFDA <- fromJSON(unzip("data/food-event-0001-of-0001.json.zip"), flatten=TRUE)The fromJSON function returns an R list with two elements: one called meta which contains some information about the data and another called results which is an R data frame with the actual data.
Let’s take a look at the enforcement events. We can see the first records in the data by
glimpse(enforceFDA$results)## Observations: 13,991
## Variables: 24
## $ classification <chr> "Class II", "Class II", "Class II",...
## $ center_classification_date <chr> "20160415", "20160415", "20160420",...
## $ report_date <chr> "20160427", "20160427", "20160427",...
## $ postal_code <chr> "78218-5415", "19044-3424", "10010-...
## $ recall_initiation_date <chr> "20160316", "20150826", "20160304",...
## $ recall_number <chr> "F-1083-2016", "F-1088-2016", "F-11...
## $ city <chr> "San Antonio", "Horsham", "New York...
## $ event_id <chr> "73576", "72085", "73471", "72916",...
## $ distribution_pattern <chr> "Texas", "AL, FL, GA, KY, NC, OH, S...
## $ recalling_firm <chr> "HEB Retail Support Center", "BIMBO...
## $ voluntary_mandated <chr> "Voluntary: Firm Initiated", "Volun...
## $ state <chr> "TX", "PA", "NY", "WA", "NJ", "", "...
## $ reason_for_recall <chr> "The product may have been under pr...
## $ initial_firm_notification <chr> "Two or more of the following: Emai...
## $ status <chr> "Ongoing", "Ongoing", "Ongoing", "O...
## $ product_type <chr> "Food", "Food", "Food", "Food", "Fo...
## $ country <chr> "United States", "United States", "...
## $ product_description <chr> "Hill Country Fare Chunk Light Tuna...
## $ code_info <chr> " UPC 041220653355 lot code 6O9FZ S...
## $ address_1 <chr> "4710 N Pan Am Expy", "255 Business...
## $ address_2 <chr> "", "", "Ste 1604", "", "", "", "",...
## $ product_quantity <chr> "5,376 units", "17,974 units", "4,7...
## $ termination_date <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA,...
## $ more_code_info <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA,...So there is a total of 13991 records in the this data with 24 fields. Let’s see what the first recalled product was:
enforceFDA$results$product_description[1]## [1] "Hill Country Fare Chunk Light Tuna in pure vegetable oil NET WT. 5 OZ (142g) packaged in a metal can."enforceFDA$results$reason_for_recall[1]## [1] "The product may have been under processed."enforceFDA$results$recalling_firm[1]## [1] "HEB Retail Support Center"So the first record was a product recalled by HEB (a grocery retail chain in Texas) which recalled a canned tuna product which may have been under-processed.
Which company had the most product recalls enforced by the FDA? We can easily get this by counting up the recalling_firm field:
RecallFirmCounts <- table(enforceFDA$results$recalling_firm)
sort(RecallFirmCounts,decreasing = T)[1:10]##
## Garden-Fresh Foods, Inc. Good Herbs, Inc.
## 633 353
## Blue Bell Creameries, L.P. Sunland, Incorporated
## 291 219
## Reser's Fine Foods, Inc. High Liner Foods Inc.
## 215 187
## Sunset Natural Products Inc. Whole Foods Market
## 173 171
## Health One Pharmaceuticals Inc Spartan Central Kitchen
## 147 140Ok - so Garden-Fresh Foods had 633 recall events. This was a simple counting exercise. Later on we will look at much more sophisticated methods for summarizing a database.
Copyright © 2017 Karsten T. Hansen. All rights reserved.