Group Summaries
 Imagine that you are three years old again and someone asks you to take a pile of Lego bricks and count the number of bricks of each color. How would you do this?
Imagine that you are three years old again and someone asks you to take a pile of Lego bricks and count the number of bricks of each color. How would you do this?
If you are a smart three year old you would intuitively use the following algorithm: First divide all bricks into separate piles of identical color, i.e., a pile of red bricks, another of green bricks and so on, and then count the number bricks in each pile. Easy.
Now imagine that you are a 25 year old analyst and your manager asks you to take the company customer database and compute average transaction size per customer for the most recent quarter. This is essentially the Lego problem and you should solve it the same way: First divide transactions into “customer piles” and then compute the average of each pile. This idea of taking a collection of objects and first sorting them and then performing some operation is also the foundation of many modern large scale computing frameworks such as MapReduce.
Group Summaries in R with dplyr
Whenever you are faced with an objective like the ones above, you should think: dplyr. This is an R package for performing group operations. Once you understand how to use dplyr, it will change your life as a data scientist and - quite possibly - permanently make you are a happier person. Seriously.
The basic structure of a dplyr statement is
- Take some data
- Define the group assignments for the data
- Perform some operation on each group
Let us try this out on some real data. You can get all the code and data for this lesson from this zip file.
Example: Open Payments
 Pharmaceutical and other health care companies often have “financial relationships” with medical doctors and hospitals. This involves payments and gifts from the company to the doctor. By federal law these transfers have to be publicly disclosed in a database. This means that anyone can download the data and inspect it. You can find the all the details and documentation if you click on the image to the right. The full data is very large so we will use a subset of it that only includes physicians licensed in the state of California. You can download this file in R format here (if you are of the attitude “to hell with it - give the me full data!”, you can get that in R format here).
Pharmaceutical and other health care companies often have “financial relationships” with medical doctors and hospitals. This involves payments and gifts from the company to the doctor. By federal law these transfers have to be publicly disclosed in a database. This means that anyone can download the data and inspect it. You can find the all the details and documentation if you click on the image to the right. The full data is very large so we will use a subset of it that only includes physicians licensed in the state of California. You can download this file in R format here (if you are of the attitude “to hell with it - give the me full data!”, you can get that in R format here).
oppr.ca <- readRDS('data/OPPR_CA.rds')This file contains a total of 223,039 payments (=number of rows) for 37,131 physicians. We will use dplyr to compute various summaries of this data.
Let us start with a simple objective: For each physician we wish to know the number and total sum of payments received. We can do this calculation as:
library(dplyr)
phys.amount <- oppr.ca %>%
group_by(Physician_Profile_ID) %>%
summarize(total.payments=sum(Total_Amount_of_Payment_USDollars),
number.payments=n())Note the use of the “%>%”-syntax. This is referred to as chaining in “R-speak”, in that each of the statements are chained together. This makes for code that is very readable - almost like reading a cook book recipe (“take the oppr.ca data frame, then group it by physician and then calculate the number and sum of payments to each physician”).
The result is a 37,131 x 3 data frame - one row for each physician. Here are the first ten rows:
Physician_Profile_ID total.payments number.payments
1 56 84.81 4
2 114 169.94 1
3 152 278.12 12
4 164 10.00 1
5 167 17942.60 7
6 176 706.60 14
7 320 117.84 6
8 441 38.26 4
9 492 72.49 4
10 493 18.31 1The first physician received $84.81 in 4 payments, while the third received $278.12 in 12 payments. By default dplyr will sort the result according to the order in which the grouping variable occurs in the source data. But we can easily change this. Suppose we wanted the results sorted in descending order of total payments. We can do this by adding another link in the chain using the arrange verb:
phys.amount <- oppr.ca %>%
group_by(Physician_Profile_ID) %>%
summarize(total.payments=sum(Total_Amount_of_Payment_USDollars),
number.payments=n()) %>%
arrange(desc(total.payments))with output (first 10 rows):
Physician_Profile_ID total.payments number.payments
1 409860 2413280.5 20
2 421550 2304899.2 4
3 40495 2001249.0 27
4 300058 1185839.7 96
5 429298 1114184.0 2
6 429305 734590.8 5
7 212521 361795.3 22
8 457294 241600.0 1
9 512530 232265.0 5
10 76646 219282.5 116Note that if we had already generated the original phys.amount data frame (without arrange), we could just have used
phys.amount <- phys.amount %>%
arrange(desc(total.payments))or - if you load the magrittr library that allows for additional chaining syntax -
library(magrittr)
phys.amount %<>% arrange(desc(total.payments))Suppose we wanted to add the information about each physicians specialty. This is obviously fixed for each physician so here we just need to grab and store the first value in the physician-specific slice of the data:
phys.amount <- oppr.ca %>%
group_by(Physician_Profile_ID) %>%
summarize(total.payments=sum(Total_Amount_of_Payment_USDollars),
number.payments=n(),
Specialty = Physician_Specialty[1]) %>%
arrange(desc(total.payments)) Physician_Profile_ID total.payments number.payments
1 409860 2413280.5 20
2 421550 2304899.2 4
3 40495 2001249.0 27
4 300058 1185839.7 96
5 429298 1114184.0 2
6 429305 734590.8 5
7 212521 361795.3 22
8 457294 241600.0 1
9 512530 232265.0 5
10 76646 219282.5 116
Specialty
1 Allopathic & Osteopathic Physicians/ Orthopaedic Surgery/ Sports Medicine
2 Allopathic & Osteopathic Physicians/ Surgery/ Surgical Critical Care
3 Other Service Providers/ Specialist
4 Allopathic & Osteopathic Physicians/ Orthopaedic Surgery
5 Allopathic & Osteopathic Physicians/ Orthopaedic Surgery/ Adult Reconstructive Orthopaedic Surgery
6 Allopathic & Osteopathic Physicians/ General Practice
7 Allopathic & Osteopathic Physicians/ Neurological Surgery
8 Allopathic & Osteopathic Physicians/ Internal Medicine/ Gastroenterology
9 Allopathic & Osteopathic Physicians/ Pediatrics
10 Allopathic & Osteopathic Physicians/ Psychiatry & Neurology/ NeurologySo the doctor with the highest total payment was an orthopaedic surgeon. In fact, 3 of the top 5 highest paid were orthopaedic surgeons.
Suppose now we only wanted to include a subset of the payments. We can do this by filtering out the rows of interest. The data contains payments of different forms (cash, stock etc.) and for different activities (consulting, speaker fee, gift, entertainment etc.). Let’s find the physicians who received the highest payments for food and beverage. We can do this by adding a filter statement to the chain:
phys.amount.food <- oppr.ca %>%
filter(Nature_of_Payment_or_Transfer_of_Value=='Food and Beverage') %>%
group_by(Physician_Profile_ID) %>%
summarize(total.payments=sum(Total_Amount_of_Payment_USDollars),
number.payments=n()) %>%
arrange(desc(total.payments))The top 10 are:
Physician_Profile_ID total.payments number.payments
1 185768 6026.23 128
2 161479 5669.56 53
3 53318 5476.66 139
4 32647 5224.77 37
5 28279 4362.86 2
6 56534 4352.18 12
7 264003 3896.13 45
8 56980 3839.69 106
9 157448 3687.22 8
10 54371 3617.46 116So far we have grouped the data by physicians. Suppose we wanted to focus the analysis on groups of physicians by specialty rather than individuals. Well, that’s easy - just group by physician specialty instead of physician ID:
spec.amount <- oppr.ca %>%
group_by(Physician_Specialty) %>%
summarize(total=sum(Total_Amount_of_Payment_USDollars),
n=n(),
n.phys=n_distinct(Physician_Profile_ID)) %>%
mutate(avg.payment=total/n,
avg.payment.phys=total/n.phys) %>%
arrange(desc(total))Here we first calculate the total amount, number of payments and number of physicians receiving payments per field. We then calculate two derived quantities: average payment size and average payment size per physician. This is done by using the mutate statement. This simply creates new variables from old ones (adding new “columns” to the data frame). Notice again the “recipe”" form of the statements:
- Take the raw data
- Group it by physician specialty
- For each specialty calculate summaries of interest
- Take the result of 3. and calculate derived quantities of interest
- Sort the result by total payment size
The top 10 specialties in terms of total payments are
Physician_Specialty
1 Other Service Providers/ Specialist
2 Allopathic & Osteopathic Physicians/ Orthopaedic Surgery
3 Allopathic & Osteopathic Physicians/ Internal Medicine
4 Allopathic & Osteopathic Physicians/ Orthopaedic Surgery/ Sports Medicine
5 Allopathic & Osteopathic Physicians/ Psychiatry & Neurology/ Psychiatry
6 Allopathic & Osteopathic Physicians/ Surgery/ Surgical Critical Care
7 Allopathic & Osteopathic Physicians/ Psychiatry & Neurology/ Neurology
8 Allopathic & Osteopathic Physicians/ Internal Medicine/ Cardiovascular Disease
9 Allopathic & Osteopathic Physicians/ Ophthalmology
10 Allopathic & Osteopathic Physicians/ Neurological Surgery
total n n.phys avg.payment avg.payment.phys
1 4227173 10139 1734 416.92207 2437.816
2 3900652 3774 918 1033.55912 4249.076
3 2922462 34928 5114 83.67104 571.463
4 2735405 419 115 6528.41368 23786.133
5 2609271 17265 2126 151.13066 1227.315
6 2306879 54 19 42719.98685 121414.699
7 2059066 6920 708 297.55287 2908.285
8 1849033 12139 1503 152.32172 1230.228
9 1615157 8336 1355 193.75685 1191.998
10 1311322 1951 425 672.12822 3085.464These results are quite interesting. Notice how the Internal Medicine and the Orthopaedic Surgery/Sports Medicine specialty have almost identical total payments ($2.9M and $2.7M), but the allocation of the total is very different: In Internal Medicine the total is spread out across 5114 physicians in 34,928 payments with an average payment per physician of $571. In Orthopaedic Surgery/Sports Medicine the total is spread out across only 115 physicians in 419 payments with an average payment per physician of $23,786.
We often do group summaries where the final output is a visualization. We can easily combine dplyr statements with ggplot2 statements:
library(ggplot2)
spec.amount %>%
slice(1:10) %>%
arrange(total) %>%
mutate(Physician_Specialty=gsub("Allopathic & Osteopathic Physicians/ ", "",Physician_Specialty),
Physician_Specialty=factor(Physician_Specialty,levels=as.character(Physician_Specialty))) %>%
ggplot(aes(x=Physician_Specialty,y=total)) +
geom_bar(stat='identity') +
coord_flip()+
ylab('Total Payments')+xlab('Specialty')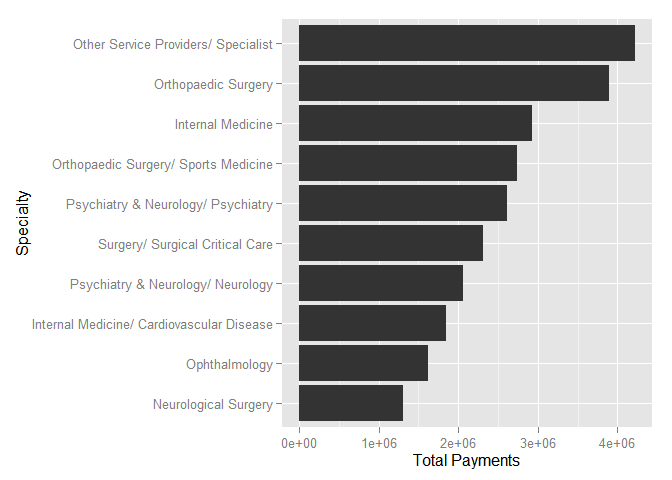
Here we take the result from the previous summary, take out the first 10 rows (using the slice statement) and then remove part of the string specifying specialty (to make for a easier to read graph). The rest of the statements will generate the plot (read the visualization section for details).
Suppose you wanted to know what the nature of payments were for each specialty. How should we do this? In this case we can group the data by both specialty and payment nature:
spec.nature.amount <- oppr.ca %>%
group_by(Physician_Specialty,Nature_of_Payment_or_Transfer_of_Value) %>%
summarize(total=sum(Total_Amount_of_Payment_USDollars),
avg.payment = mean(Total_Amount_of_Payment_USDollars),
n=n(),
n.phys=n_distinct(Physician_Profile_ID)) %>%
mutate(avg.payment.phys = total/n.phys) %>%
arrange(desc(avg.payment.phys))In this case the result is sorted on average physician payment within physician specialty. Here is the result for Anesthesiologists:
spec.nature.amount %>% filter(Physician_Specialty=='Allopathic & Osteopathic Physicians/ Anesthesiology')## total avg.payment n n.phys avg.payment.phys
## 1 248752.88 2487.52880 100 33 7537.96606
## 2 54325.00 2469.31818 22 8 6790.62500
## 3 15572.02 1038.13467 15 4 3893.00500
## 4 52305.82 1025.60431 51 19 2752.93789
## 5 36976.11 1056.46029 35 16 2311.00688
## 6 41888.99 410.67637 102 29 1444.44793
## 7 485.16 485.16000 1 1 485.16000
## 8 51217.84 38.22227 1340 602 85.07947
## 9 6927.01 54.97627 126 96 72.15635where the payment codes are
## [1] "Consulting Fee"
## [2] "Compensation for serving as faculty or as a speaker for a non-accredited and noncertified continuing education program"
## [3] "Gift"
## [4] "Compensation for services other than consulting, including serving as faculty or as a speaker at a venue other than a continuing education program"
## [5] "Honoraria"
## [6] "Travel and Lodging"
## [7] "Royalty or License"
## [8] "Food and Beverage"
## [9] "Education"For physicians specializing in Internal Medicine we get
spec.nature.amount %>% filter(Physician_Specialty=='Allopathic & Osteopathic Physicians/ Internal Medicine')## total avg.payment n n.phys avg.payment.phys
## 1 167992.00 167992.00000 1 1 167992.00000
## 2 51000.00 25500.00000 2 2 25500.00000
## 3 131892.86 2536.40115 52 24 5495.53583
## 4 623899.03 998.23845 625 137 4554.00752
## 5 843201.61 1663.11955 507 330 2555.15639
## 6 206882.27 323.25355 640 177 1168.82638
## 7 71939.19 705.28618 102 64 1124.04984
## 8 1500.00 500.00000 3 3 500.00000
## 9 1548.19 309.63800 5 4 387.04750
## 10 783207.69 25.13665 31158 4823 162.39015
## 11 200.25 50.06250 4 4 50.06250
## 12 39198.91 21.43188 1829 912 42.98126## [1] "Current or prospective ownership or investment interest"
## [2] "Grant"
## [3] "Compensation for serving as faculty or as a speaker for a non-accredited and noncertified continuing education program"
## [4] "Compensation for services other than consulting, including serving as faculty or as a speaker at a venue other than a continuing education program"
## [5] "Consulting Fee"
## [6] "Travel and Lodging"
## [7] "Honoraria"
## [8] "Charitable Contribution"
## [9] "Gift"
## [10] "Food and Beverage"
## [11] "Entertainment"
## [12] "Education"Exercise Open Payments1
What are top 5 manufacturers in terms of payments? (you can use the variable Submitting_Applicable_Manufacturer_or_Applicable_GPO_Name to id manufacturers)
What is the structure of payments for these 5 manufacturers? (how many payments, total sum, what type of payments?)
Example: New York Bike Share

- Citi bikes: Public bikes in New York City
- Data contains all rides in August 2015.
- Start and end time, start and end location, user type
- Birth year and gender for subscribers
- 419 stations
- 1,179,044 total rides
- 7831 bikes
In the following we will visualize various aspects of this data. Let’s start by loading the data and taking a peek at it:
citibike <- readRDS('data/201508.rds')
glimpse(citibike[1,])## Observations: 1
## Variables: 17
## $ tripduration (int) 1202
## $ start.time (chr) "8/1/2015 00:00:04"
## $ stop.time (chr) "8/1/2015 00:20:07"
## $ start.station.id (int) 168
## $ start.station.name (chr) "W 18 St & 6 Ave"
## $ start.station.latitude (dbl) 40.73971
## $ start.station.longitude (dbl) -73.99456
## $ end.station.id (int) 385
## $ end.station.name (chr) "E 55 St & 2 Ave"
## $ end.station.latitude (dbl) 40.75797
## $ end.station.longitude (dbl) -73.96603
## $ bikeid (int) 23253
## $ usertype (chr) "Subscriber"
## $ birth.year (int) 1987
## $ gender (chr) "male"
## $ start.hour (int) 0
## $ weekday (fctr) SatThe first trip was 1202 seconds long and started just after midnight on August 1, 2015. This was a trip made with bike number 23253, which was checked out at station 168 (located at W 18 St & 6 Ave). The trip ended at station 385 (E 55 St & 2 Ave). This trip was made by a male system subscriber born in 1987.
Let’s start by counting the number trips made for each bike in the system. We will order the result in descinding fashion:
bike.trip.count.s <- citibike %>%
count(bikeid) %>%
arrange(desc(n))The count command simply counts the number of rows for each instance of the bikeid variable (and creates a variable called n). We then sort the result. The top 10 most popular bikes were
bike.trip.count.s %>%
slice(1:10)## Source: local data frame [10 x 2]
##
## bikeid n
## (int) (int)
## 1 22251 475
## 2 22301 475
## 3 24066 474
## 4 22125 472
## 5 22300 472
## 6 22319 471
## 7 24021 465
## 8 22306 464
## 9 22515 463
## 10 22502 461Note that if you want the results variable to be called something different than n you need to use the group_by approach:
bike.trip.count.s <- citibike %>%
group_by(bikeid) %>%
summarize(n.trips = n()) %>%
arrange(desc(n.trips))Exercise Bike1
- Count the number of trips originating from each bike station
- What are the 5 busiest bike stations?
Now let’s look at trip durations. The average trip duration (in minutes) across all trips is
mean(citibike$tripduration)/60## [1] 16.95798Ok - just about 17 minutes. How long can trips be? The 10 longest trips were
citibike %>%
arrange(desc(tripduration)) %>%
slice(1:10) %>%
select(tripduration) %>%
mutate(hours=tripduration/3600)## Source: local data frame [10 x 2]
##
## tripduration hours
## (int) (dbl)
## 1 2842280 789.5222
## 2 2712082 753.3561
## 3 2555456 709.8489
## 4 2453796 681.6100
## 5 2133856 592.7378
## 6 2041702 567.1394
## 7 1795721 498.8114
## 8 1774865 493.0181
## 9 1745724 484.9233
## 10 1622701 450.7503Those are some long bike trips! It is not clear exactly what sort of trips these are, but clearly they are outliers and does not represent typical behavior. Let’s see how many trips are longer than 12 hours:
sum(citibike$tripduration > 12*3600) ## [1] 610sum(citibike$tripduration > 12*3600)/nrow(citibike) ## [1] 0.0005173683There are only 610 trips longer than 12 hours - representing only 0.05% of the total number of trips. If we abstract from these outliers, the average trip is
citibike %>%
filter(tripduration < 12*3600) %>%
summarize(mean.trip = mean(tripduration)/60)## Source: local data frame [1 x 1]
##
## mean.trip
## (dbl)
## 1 15.6424So the average trip is 15.6 minutes. You can get some other quick summary statistics for the data by using summary:
citibike %>%
filter(tripduration < 12*3600) %>%
mutate(minutes=tripduration/60) %>%
select(minutes) %>%
summary()## minutes
## Min. : 1.000
## 1st Qu.: 6.917
## Median : 11.333
## Mean : 15.642
## 3rd Qu.: 19.067
## Max. :719.683The shortest trip is 1 minute while half of all trips are less than 11 minutes. There are still some large outliers in the data (notice how much larger the mean is compare to the median). To see where the outlier trips are, you can simply compute various percentiles of the data, e.g.,
quantile(citibike$tripduration/60, probs = c(0.5,0.9,0.95,0.975,0.99,0.995,1.0))## 50% 90% 95% 97.5% 99% 99.5%
## 11.33333 28.46667 36.03333 47.41667 80.90000 126.51667
## 100%
## 47371.33333Ok - so 95% of all trips are less than 36 minutes, while 99% of all trips are less than 81 minutes. Only 0.5% of trips are longer than 126.5 minutes. This is all telling us the same story - there is a long right tail of outliers. Another way of saying this is that if we plot a histogram of trip durations, almost the data is gone by the time we reach 2 hours. Let’s check:
citibike %>%
filter(tripduration < 2*3600) %>%
ggplot(aes(x=tripduration/60)) + geom_histogram(binwidth=0.5)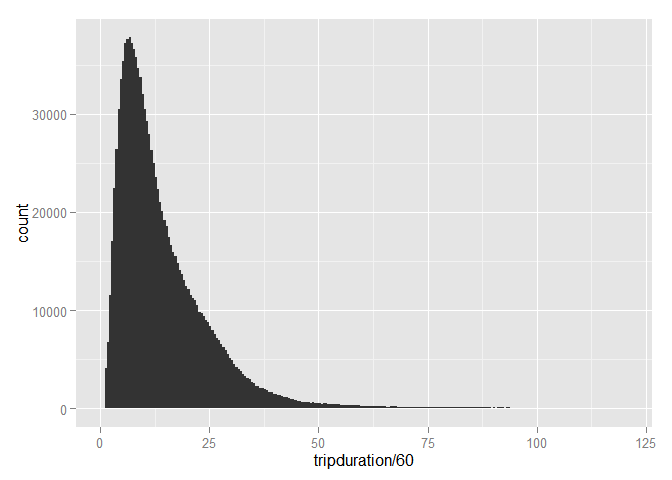
(Note: you can change the binwidth to change the smoothness of the histogram). The vast majority of trips are less than 30 minutes with very trips lasting more than 2 hours.
Next, let’s look at user behavior throughout the day. For example, we can calculate number of trips and trip duration by hour of day:
hour.activity <- citibike %>%
filter(tripduration < 12*3600) %>%
group_by(start.hour) %>%
summarise(n.trips=n(),
mean.trip.time=mean(tripduration/60))Exercise Bike2
- Calculate number of trips and trip duration by day of week and user type
- For what hour of the day do subscribers take the longest/shortest trips?
Exercise Bike3
- Calculate average trip time by day of week for each gender.
- Do men and women exhibit similar behavior?