Data Management in R
Raw data is typically not available as R data files. If your data has been extracted from a database, you will most likely receive it as flat text files, e.g., csv files. Data recording web activity is often stored in a format called json. In this section we will look at how to easily read data files into R’s memory and how to store them as R databases.
Reading Data into R
In the following we will use some data from the NFL as example data. You can download all data and code for this lesson as a zip folder here.
Reading R data files
If your data is already stored in an R database file, you can read it in with the load command:
FileName <- 'c:/mydata/2013_nfl.rda'
load(FileName)This will load the data frames (or other R objects) contained in the R database “2013_nfl.rda”. Note that this database may contain one or several data frames. There are several advantages to storing your data as an R database: They are highy compressed files and R will read them into memory very fast. If you have obtained your data in another data format, it is recommended to start your analysis by converting all data to an R database (see below for how you do this).
Digression: Paths in R
Note that in the example above we provided the full file path and name when loading the data. If the file you are loading is located in the current working directory, then you can simply write the file name:
FileName <- '2013_nfl.rda'
load(FileName)Don’t know your current working directory? Simply execute the command
getwd()in the R console. If the file is located in a subdirectory of your current work directory called - for example - “data” - then you can write
FileName <- 'data/2013_nfl.rda'
load(FileName)It is good practice to start out a data analytics project by defining a new folder on your local drive, e.g., “SuperDuperAnalytics”. Then set the working directory to be this folder. Then you can have subfolders called “data”, “code”, “results” etc.
One feature of the load command that is sometimes annoying, is that you don’t know the names of the R objects, e.g., data frames, that you are loading until after you have read them into memory. This can create problems if you are reading in multiple .rda files in sequence and some of them have objects with identical names. An alternative is to save and read R data using files where there is only one single object rather than multiple objects. If R data has been saved using the saveRDS command (see below for more on this), you can read it in as
nfl.data <- readRDS('c:/mydata/2013_nfl.rds')The advantage here is that you have control over what to call the R data frame when loaded in memory.
Reading CSV files
It is straightforward to read a csv file into R’s memory:
FileName <- 'c:/mydata/NFL/data/2013 NFL Play-by-Play Data.csv'
nfl.data <- read.csv(FileName)If the first line of the csv file contains column names, R will automatically assign these as variable names in the resulting data.frame:
names(nfl.data)## [1] "Date"
## [2] "Tm"
## [3] "Opp"
## [4] "Quarter"
## [5] "Time"
## [6] "Down"
## [7] "ToGo"
## [8] "Side.of.Field"
## [9] "Yard.Marker"
## [10] "Tm.Score"
## [11] "Opp.Score"
## [12] "Detail"
## [13] "Yds"
## [14] "Play.Type"
## [15] "Pass.Result"
## [16] "Pass.Distance"
## [17] "Pass.Location"
## [18] "Run.Location"
## [19] "Turnover"
## [20] "Fumble"
## [21] "Interception"
## [22] "Passer"
## [23] "Intended.Receiver"
## [24] "Receiver"
## [25] "Targeted.Receiver"
## [26] "Rusher"
## [27] "Touchdown"
## [28] "First.Down"
## [29] "Time.Under"
## [30] "Score.Differential"
## [31] "Absolute.Score.Differential"
## [32] "Game.Week"
## [33] "Team.Game.Location"
## [34] "Rush.Attempt"
## [35] "Pass.Attempt"
## [36] "Reception"
## [37] "Interception.Thrown"
## [38] "Target"
## [39] "Fumble.Count"
## [40] "Sack"
## [41] "Len"
## [42] "Yard.Line"
## [43] "Playmaker"
## [44] "Touches"
## [45] "Play.Attempts"
## [46] "Playmaker.Position"
## [47] "Yards.Gained"
## [48] "Play.Location"
## [49] "Touchdown.Count"
## [50] "Play.Percent.of.Goal"
## [51] "First.Down.Count"
## [52] "Conversion.Count"
## [53] "Goal.To.Go"
## [54] "Success.Count"
## [55] "Penalty.Removed.Detail"
## [56] "Len.Penalty"
## [57] "Playmaker.Fantasy.Points"
## [58] "Passer.Fantasy.Points"
## [59] "Fantasy.Points.Rushing.Yards"
## [60] "Fantasy.Points.Receiving.Yards"
## [61] "Fantasy.Points.Receptions"
## [62] "Fantasy.Points.Rushing.TD"
## [63] "Fantasy.Points.Receiving.TD"
## [64] "Fantasy.Points.Playmaker.Fumble"
## [65] "Fantasy.Points.Passer.Yards"
## [66] "Fantasy.Points.Passer.TD"
## [67] "Fantasy.Points.Passer.Interception"
## [68] "Team.Game.Number"If you have very large csv files (in the GB range), you may want to swith to the read_csv function in the readr library:
library(readr)
nfl.data <- read_csv(FileName)This is quite a bit faster than than the base read.csv function and allows for fine control over variable formatting (see the documentation for the readr package). A cool feature of the readr library is that you can read raw data stored in zip files without “unzipping” them first:
ZipFileName <- 'c:/mydata/NFL/2013 NFL Play-by-Play Data.zip'
nfl.data <- read_csv(ZipFileName)Using RIO
An alternative to using the above functions in R is to use RIO. This is an R package that provides data input functions for a variety of data formats.
Storing data in R format
You can store data in R’s compressed database format using the save command:
save(nfl.data,file='c:/mydata/nfl_data.rda')You can store multiple objects in one file. Suppose you had two different versions of the data, nfl.data.V1 and nfl.data.V2. Then you can store both data frames in one file with
save(nfl.data.V1,nfl.data.V2,file='c:/mydata/nfl_data.rda')When you then use
load('c:/mydata/nfl_data.rda')the data frames nfl.data.V1 and nfl.data.V2 will appear in R’s memory.
To save only a single object so that you can later rename it at the time of loading, use the saveRDS command:
saveRDS(nfl.data,file='c:/mydata/nfl_data.rds')In this case you can only save a single object.
General Recommendations
Always start by converting raw data to R data files. You can then start any subsequent data analysis by reading in the data in R format rather than in raw format. This will be much faster. Save your code for converting raw data to R format in case you want to go back to check for errors: Make an R source file called something like convert_data_to_R.r. This file should contain the code you used to (a) read in the raw data, (b) perform any initial data clean-up or transformations and (c) save data in R format.
A good prescription is to save large data files using the saveRDS command. You can then load them later using a customized name.
Merging Data
You will often have a need for merging data frames. For example, suppose you have a customer transaction file where each customer is identified by some unique id. In another file you may have other information on each customer, e.g., address, type, length of relationship etc. If you want to link customer characteristics to transaction behavior, you will need to merge the two files. In this case, we would merge on the unique customer id.
You can merge data frames in R using the join command in the dplyr library. As an example, suppose we first count the number of turnovers for each NFL team in the 2013 season (for details on the group_by command see the group summaries section):
library(dplyr)
turnover.total <- nfl.data %>%
group_by(Tm) %>%
summarize(Turnovers=sum(Turnover))The result is
## Tm Turnovers
## 1 49ers 21
## 2 Bears 29
## 3 Bengals 36
## 4 Bills 40
## 5 Broncos 29
## 6 Browns 34
## 7 Buccaneers 25
## 8 Cardinals 39
## 9 Chargers 21
## 10 Chiefs 26
## 11 Colts 20
## 12 Cowboys 27
## 13 Dolphins 31
## 14 Eagles 28
## 15 Falcons 31
## 16 Giants 50
## 17 Jaguars 38
## 18 Jets 37
## 19 Lions 46
## 20 Packers 31
## 21 Panthers 21
## 22 Patriots 29
## 23 Raiders 39
## 24 Rams 26
## 25 Ravens 36
## 26 Redskins 45
## 27 Saints 19
## 28 Seahawks 27
## 29 Steelers 29
## 30 Texans 41
## 31 Titans 36
## 32 Vikings 37Now let’s read in another file with information on each teams win-loss percentage in the same season:
nfl.record <- read_csv(file = 'data/NFL_2013_Record.csv')
nfl.record## Source: local data frame [32 x 3]
##
## Tm Record Conference
## (chr) (dbl) (chr)
## 1 Eagles 0.625 NFC
## 2 Cowboys 0.500 NFC
## 3 Giants 0.438 NFC
## 4 Redskins 0.188 NFC
## 5 Packers 0.531 NFC
## 6 Bears 0.500 NFC
## 7 Lions 0.438 NFC
## 8 Vikings 0.344 NFC
## 9 Panthers 0.750 NFC
## 10 Saints 0.688 NFC
## .. ... ... ...We can now merge the two data frames on the variable Tm:
turnover.total.record <- turnover.total %>%
left_join(nfl.record,by="Tm")This will return the following data frame:
## Tm Turnovers Record Conference
## 1 49ers 21 0.750 NFC
## 2 Bears 29 0.500 NFC
## 3 Bengals 36 0.688 AFC
## 4 Bills 40 0.375 AFC
## 5 Broncos 29 0.813 AFC
## 6 Browns 34 0.250 AFC
## 7 Buccaneers 25 0.250 NFC
## 8 Cardinals 39 0.625 NFC
## 9 Chargers 21 0.563 AFC
## 10 Chiefs 26 0.688 AFC
## 11 Colts 20 0.688 AFC
## 12 Cowboys 27 0.500 NFC
## 13 Dolphins 31 0.500 AFC
## 14 Eagles 28 0.625 NFC
## 15 Falcons 31 0.250 NFC
## 16 Giants 50 0.438 NFC
## 17 Jaguars 38 0.250 AFC
## 18 Jets 37 0.500 AFC
## 19 Lions 46 0.438 NFC
## 20 Packers 31 0.531 NFC
## 21 Panthers 21 0.750 NFC
## 22 Patriots 29 0.750 AFC
## 23 Raiders 39 0.250 AFC
## 24 Rams 26 0.438 NFC
## 25 Ravens 36 0.500 AFC
## 26 Redskins 45 0.188 NFC
## 27 Saints 19 0.688 NFC
## 28 Seahawks 27 0.813 NFC
## 29 Steelers 29 0.500 AFC
## 30 Texans 41 0.125 AFC
## 31 Titans 36 0.438 AFC
## 32 Vikings 37 0.344 NFCBy default left_join will return all columns from both data frames. If there are rows in the “left” data frame (here turnover.total) that do not have a match in the “right” data frame (here nfl.record), then these will have a NA in the corresponding row. To see this in action, let’s remove two teams from the nfl.record data frame and then merge:
nfl.record.miss <- nfl.record %>%
filter(!Tm %in% c('Bears','Chiefs'))
turnover.total.record.miss <- turnover.total %>%
left_join(nfl.record.miss,by="Tm")The result is now
## Tm Turnovers Record Conference
## 1 49ers 21 0.750 NFC
## 2 Bears 29 NA <NA>
## 3 Bengals 36 0.688 AFC
## 4 Bills 40 0.375 AFC
## 5 Broncos 29 0.813 AFC
## 6 Browns 34 0.250 AFC
## 7 Buccaneers 25 0.250 NFC
## 8 Cardinals 39 0.625 NFC
## 9 Chargers 21 0.563 AFC
## 10 Chiefs 26 NA <NA>
## 11 Colts 20 0.688 AFC
## 12 Cowboys 27 0.500 NFC
## 13 Dolphins 31 0.500 AFC
## 14 Eagles 28 0.625 NFC
## 15 Falcons 31 0.250 NFC
## 16 Giants 50 0.438 NFC
## 17 Jaguars 38 0.250 AFC
## 18 Jets 37 0.500 AFC
## 19 Lions 46 0.438 NFC
## 20 Packers 31 0.531 NFC
## 21 Panthers 21 0.750 NFC
## 22 Patriots 29 0.750 AFC
## 23 Raiders 39 0.250 AFC
## 24 Rams 26 0.438 NFC
## 25 Ravens 36 0.500 AFC
## 26 Redskins 45 0.188 NFC
## 27 Saints 19 0.688 NFC
## 28 Seahawks 27 0.813 NFC
## 29 Steelers 29 0.500 AFC
## 30 Texans 41 0.125 AFC
## 31 Titans 36 0.438 AFC
## 32 Vikings 37 0.344 NFCIf you want the result only for teams where there is a positive match, you can use inner_join instead:
turnover.total.record.miss <- turnover.total %>%
inner_join(nfl.record.miss,by="Tm")This results in
## Tm Turnovers Record Conference
## 1 49ers 21 0.750 NFC
## 2 Bengals 36 0.688 AFC
## 3 Bills 40 0.375 AFC
## 4 Broncos 29 0.813 AFC
## 5 Browns 34 0.250 AFC
## 6 Buccaneers 25 0.250 NFC
## 7 Cardinals 39 0.625 NFC
## 8 Chargers 21 0.563 AFC
## 9 Colts 20 0.688 AFC
## 10 Cowboys 27 0.500 NFC
## 11 Dolphins 31 0.500 AFC
## 12 Eagles 28 0.625 NFC
## 13 Falcons 31 0.250 NFC
## 14 Giants 50 0.438 NFC
## 15 Jaguars 38 0.250 AFC
## 16 Jets 37 0.500 AFC
## 17 Lions 46 0.438 NFC
## 18 Packers 31 0.531 NFC
## 19 Panthers 21 0.750 NFC
## 20 Patriots 29 0.750 AFC
## 21 Raiders 39 0.250 AFC
## 22 Rams 26 0.438 NFC
## 23 Ravens 36 0.500 AFC
## 24 Redskins 45 0.188 NFC
## 25 Saints 19 0.688 NFC
## 26 Seahawks 27 0.813 NFC
## 27 Steelers 29 0.500 AFC
## 28 Texans 41 0.125 AFC
## 29 Titans 36 0.438 AFC
## 30 Vikings 37 0.344 NFCThere is also a semi_join and anti_join but they tend to be less useful (for the details see the help for join in the dplyr library).
What is the result? Let’s do a quick visualization (you will learn how to do this in the Data Visualization section):
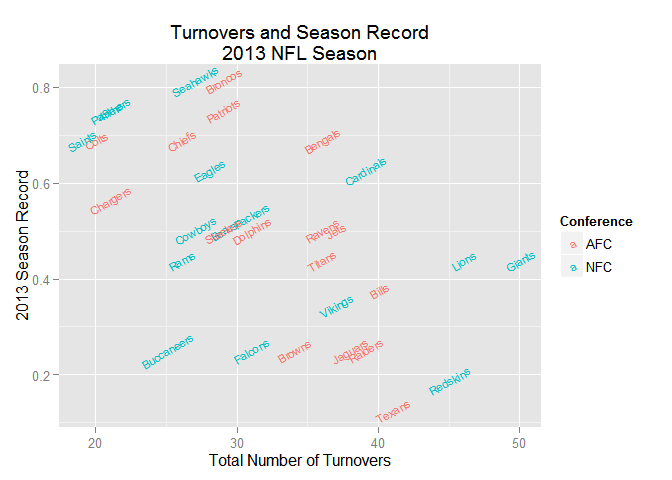
Exercise
What is the relationship between a quarterback’s interception rate (defined as number of interceptions thrown divided by the total number of passes) and the quaterback’s age and experience?
First we load data on frequently playing quarterbacks’ interception rate:
FileName <- 'data/interceptions_qb.rds'
interceptions.qb <- readRDS(FileName)Next load data on NFL player characteristics:
FileName <- 'data/NFL_2013_Player_Census.rds'
player.data <- readRDS(FileName)Hint: To perform the relevant merge, note that the player name variable has a different name in the two data frames to be merged. To find out how to solve this problem look in the help section for left_join (write help(“left_join”) in the R console).